Qwen has just unveiled WorldPM, a groundbreaking 72.88 billion parameter preference model, and it’s making waves across the AI community. In this blog, we’ll take a concise yet insightful look into what this model is, how it works, and why it matters.
What Is a Preference Model?
A preference model isn’t a chatbot or a typical text generator. Instead, it acts as a scoring engine — trained to evaluate and rank candidate responses based on human preferences. It assigns a scalar score to each candidate output, reflecting how closely the text aligns with what humans generally prefer.
What makes this unique is that it has been pre-trained on over 15 million human pairwise comparisons sourced from various online forums. These comparisons help the model learn nuanced patterns of preferred human communication — not just generating plausible responses but judging which ones are better.
Why Is WorldPM Special?
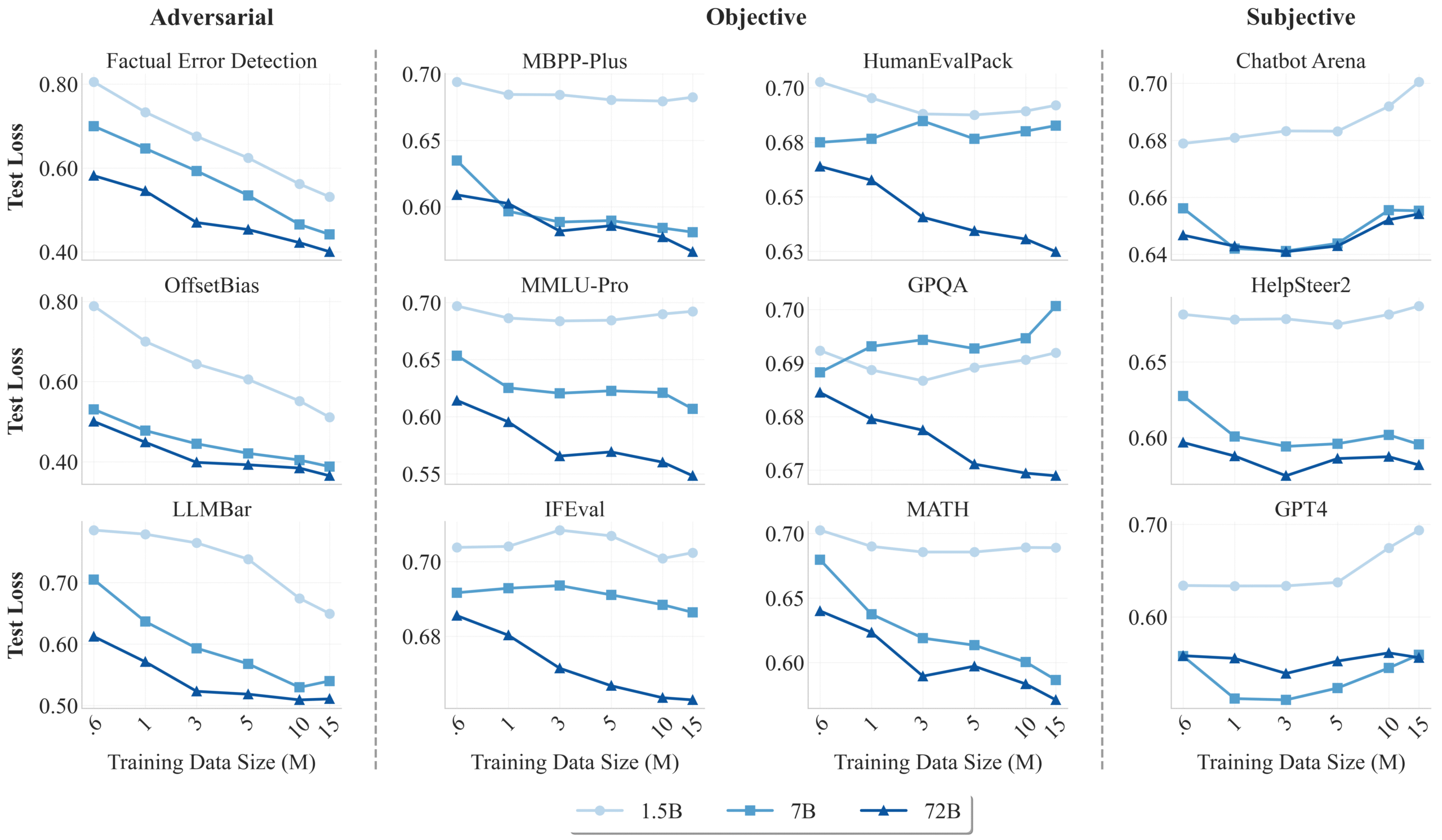
What surprised many — including myself — is its massive scale. At 72.88 billion parameters, it is one of the largest preference models ever released. Traditionally, preference models are smaller (often <10B), so this is a significant leap, likely aimed at solving more complex and nuanced alignment tasks.
WorldPM demonstrates power-law scaling loss similar to autoregressive models, meaning the model gets better as training data and size increase. This offers more robust and fine-grained ranking capabilities.
How It Works: A Quick Example
Let’s say the user prompt is:
“Tips for better sleep.”
Two responses are given:
- Response A: “Set a consistent bedtime and wake-up schedule. Avoid screens an hour before bed. Keep the bedroom cool and dark. Start with these habits and you should notice improvements within a week.”
- Response B: “Just try sleeping earlier or take some pills if you can’t sleep. Maybe watch TV until you get tired, I don’t know.”
WorldPM ranks Response A significantly higher, assigning a positive score, while Response B receives a negative score — showing the model’s preference for helpful, thoughtful responses.
Fine-Tuned Variants of WorldPM
| Model | Dataset | Training Scale |
|---|---|---|
| WorldPM-72B-HelpSteer2 | HelpSteer2 | 7K |
| WorldPM-72B-UltraFeedback | UltraFeedback | 100K |
| WorldPM-72B-RLHFLow | RLHFLow | 800K |
Along with the base model, Qwen has released three fine-tuned versions, each optimized for different alignment workflows:
1. HelpSteer Model
- Fine-tuned on the HelpSteer dataset, which is designed to make models more helpful, factually accurate, and coherent.
- Allows customization of response complexity and verbosity.
- Note: Dataset is Creative Commons Attribution 4.0 (CC BY 4.0), but the model is Apache 2.0 — double-check licensing for commercial use.
2. UltraFeedback Model
- Fine-tuned on the UltraFeedback dataset, consisting of over 64,000 prompts from sources like UltraChat, ShareGPT, EvolveInstruct, and TruthfulQA.
- Focuses on diverse, fine-grained preference training.
- Ideal for powering reward models or critique models in advanced AI systems.
3. RLHF Workflow Model
- Tailored for Reinforcement Learning with Human Feedback (RLHF).
- Uses datasets with labeled ‘chosen’ and ‘rejected’ answers, making it suitable for training reward models that align generation with human judgment.
Installation & Access
If you have a multi-GPU setup, you can try running the model yourself:
- Install the latest
transformerslibrary from GitHub. - Download the model and tokenizer from Hugging Face or ModelScope.
- Documentation and GitHub repo are available (though still minimal, as the release is fresh).
- Licensing: The base model is under Apache 2.0, a permissive license ideal for commercial use — but verify dataset licenses before deploying in production.
The Research Paper
Qwen has also released a detailed research paper explaining the model’s architecture, training process, and evaluation metrics. It’s an excellent resource for those wanting to dive deeper into the technical aspects.
Why This Matters
WorldPM is a milestone in preference modeling, not just for its size but for its versatility. Whether you’re ranking responses, steering generation with RLHF, or training a reward model, WorldPM offers a high-capacity, flexible solution.
While some may see its scale as overkill, others will find value in its ability to capture subtle nuances in human preference — essential for building truly aligned AI systems.
What’s Next?
As of now, there’s no API or hosted playground available, but we expect Qwen Chat or other integrations to follow soon.